
Cross-modal music retrieval remains a challenging task for current search engines. Existing engines match music tracks using coarse-granularity retrieval of metadata, like pre-defined tags and genres. These methods face difficulties handling fine-granularity contextual queries. We propose a novel dataset of 66,048 image-music pairs for cross-modal music retrieval and introduce a hybrid-granularity retrieval framework using contrastive learning. Our method outperforms previous approaches, ensuring superior image-music alignment.
Large-scale music platforms often use metadata-based search engines, but these methods struggle with context-specific queries. To solve this issue, we present a novel approach that learns hybrid-granularity context alignment between images and music through contrastive learning.
We created the MIPNet dataset, consisting of 66,048 image-music pairs. Each pair includes an image and a corresponding 10-second music clip, with both being labeled for emotional context. These pairs enable the training of cross-modal retrieval models to better align images with their associated music tracks.

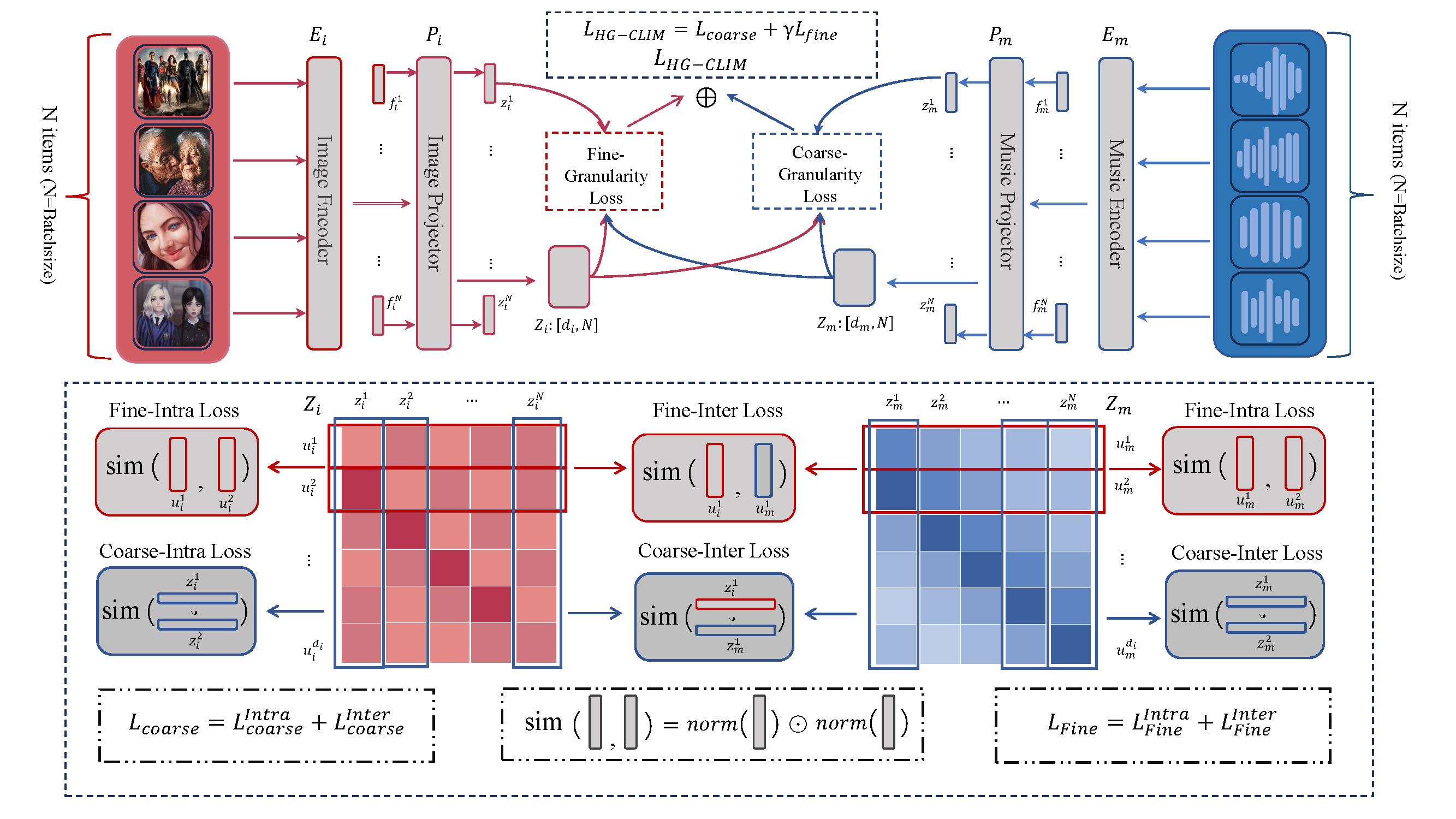
The HG-CLIM framework incorporates both coarse-granularity and fine-granularity retrieval methods. It utilizes ConvNext and PaSST encoders to extract image and music features, which are projected into a shared embedding space for better cross-modal alignment.
We tested our HG-CLIM framework on the MIPNet dataset using various metrics such as MRR, R@10, and P@1. The results show that our method significantly outperforms previous models like EMO-CLIM and VM-NET.
| Method | MRR | R@10 | P@1 |
|---|---|---|---|
| EMO-CLIM | 0.0804 / 0.0812 | 0.1592 / 0.1633 | 0.0831 / 0.0791 |
| VM-NET | 0.3279 / 0.3165 | 0.6463 / 0.6258 | 0.2001 / 0.2057 |
| HG-CLIM (ours) | 0.5124 / 0.5104 | 0.8080 / 0.8082 | 0.2931 / 0.2910 |
Our method also shows compeitive abilitiy in emotion-based music retrieval task.
| Method | MRR | R@10 | P@1 |
|---|---|---|---|
| MMTS | 0.4575 / 0.4807 | 0.6887 / 0.7123 | 0.4070 / 0.4188 |
| EMO-CLIM | 0.4619 / 0.5072 | 0.8237 / 0.7986 | 0.4917 / 0.4935 |
| HG-CLIM (ours) | 0.4765 / 0.5123 | 0.8215 / 0.7921 | 0.5033 / 0.5094 |
The results of the ablation studies demonstrate that the fine-granularity loss significantly aids the model in learning implicit context-specific information.
| Loss | MRR (I → M) | MRR (M → I) |
|---|---|---|
| Baseline | 0.3164 | 0.2662 |
| Baseline + Lintrafine | 0.3272 | 0.3196 |
| Baseline + Linterfine | 0.4793 | 0.4761 |
| Baseline + Lfine (HG-CLIM) | 0.5124 | 0.5104 |
Our work introduces HG-CLIM, a hybrid-granularity context alignment framework for image-based music retrieval. This approach enables retrieval tasks that align images and music on both coarse and fine-granularity levels, demonstrating state-of-the-art performance.